
Python
Python es un lenguaje interpretado y orientado a objetos cuyo principal objetivo es producir software de una forma fácil y rápida, así de sencillo. Python es rápido. Además, siendo bastante fácil de aprender y utilizar, lo hacen un lenguaje de programación perfecto para principiantes que quieran aprender programación.Actualmente, la versión de Python más actualizada es la 3.5.1. Sin embargo, mucha gente (como yo de forma habitual) utiliza otra versión más antigua, de la familia 2.7.X. Esto se debe a que el paso de Python 2 a Python 3 llevó a una remodelación de algunos elementos del lenguaje. De todas formas, la rama de Python 2 aún sigue actualizándose, siendo la más actual la versión 2.7.11.
Pese a que estas diferencias existen, ambas ramas comparten el mismo paradigma y el mismo enfoque, y la sintaxis es prácticamente igual. Podéis usar cualquiera de estas dos versiones libremente, y los scripts escritos en una o en otra deberían poder usarse (con ciertos límites) en ambas versiones sin apenas modificaciones.
Dicho esto, soltaré una frase que me oiréis decir de vez en cuando: Saber programar no es saber un lenguaje. Cuando aprendes a programar, el lenguaje te da un poco igual. Esto, que puede sonar muy raro, al final tiene sentido; programar es comprender el flujo que tiene que seguir tu programa para solucionar tu problema de una forma ágil y fiable, y esto es igual en cualquier lenguaje de programación.
¡No me tengáis en cuenta los sermones! :)
Decir también que esta entrada y las que seguirán no pretenden realizar un paso-a-paso por la programación en Python; para ello puedo recomendar libros y manuales que os ayudarán mucho. Sin ir mas lejos, Python para todos de Raúl González Duque es el mejor manual que me he encontrado, y lo podéis descargar de forma gratuita. Lo que sí intentaré es justificar y explicar los elementos estructurales de la herramienta.
En Fwhibbit todos utilizamos Python en mayor o menor medida a la hora de crear herramientas y pruebas de concepto, como la que os traigo hoy. Este script, que podéis encontrar en mi perfil de GitHub, permite obtener metadatos de ficheros con extensión pdf y docx. Por supuesto, el script es ampliable (en un futuro seguramente se amplíe) con nuevos formatos soportados; os lo brindo como prueba de concepto a la recolección de metadatos.
Metadatos
Hablando de ello, ¿qué es eso de metadatos? Los metadatos son una serie de marcas o etiquetas en un archivo que describen diversa información acerca del mismo. La información que arrojan puede ser muy variada dependiendo de cómo se creó el archivo y con qué formato y extensión: autor, fecha de creación, programa y sistema operativo origen... La información que puede arrojar un solo fichero puede dejarnos muy sorprendidos y ser clave para la recolección de información de un objetivo.El script metadatos.py
El proceso que suelo utilizar a la hora de realizar este tipo de scripts (que puede no ser la mejor, ¡uno no es perfecto!) es comenzar escribiendo la función principal del programa (la función main de toda la vida y que os sonará a los que sois más de Java o C), que verificará los argumentos que le pasamos al script; en este caso, es la dirección (absoluta o relativa) a un directorio que contendrá los ficheros a analizar. |
| Función principal del script |
Una vez hecho esto, la función main invocará a la función que abre y realiza el análisis del fichero en sí, que llamo printMeta(target). Recibe como parámetro el directorio objetivo una vez comprobado y filtrado por la función principal. Una vez comprobado que el objetivo existe, realizará un recorrido en profundidad en su interior (utilizo la función os.walk(target), extremadamente útil en estos casos) y, por cada fichero encontrado, analizará su extensión e invocará a la función correspondiente para la impresión de metadatos si es una extensión soportada.
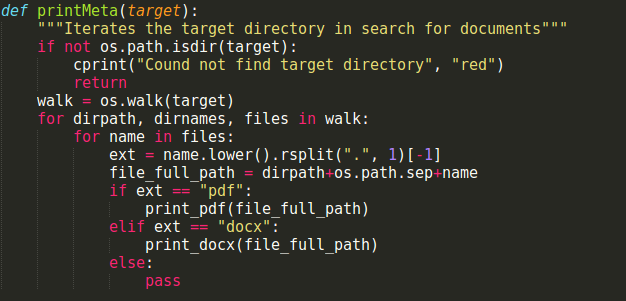 |
| Función de apertura para analizar el directorio y ficheros encontrados |
Por último, las funciones print_doxc(file_full_path) y print_pdf(file_full_path) reciben como parámetro la dirección completa del fichero objetivo e imprimen todos los metadatos encontrados. Para esto, hacemos uso de los módulos externos python-docx y PyPDF2, que proporcionan medios para crear, modificar y borrar ficheros .docx y .pdf respectivamente. En nuestro caso, servirán para analizar un fichero que ya existe y extraer toda la información en forma de metadatos que contengan, imprimiendo por pantalla los datos encontrados.
 |
| Análisis de metadatos en PDF |
 |
| Análisis de metadatos en PDF |
A continuación, la ejecución del script en nuestra distribución Linux favorita (funcionará en Windows excepto por la coloración de los resultados, dependiendo de nuestra shell):
 |
| Ejecución del script sobre un directorio |
Cabe destacar la importancia de varias cosas que podéis apreciar en el script como buenas prácticas que os animo encarecidamente a seguir:
- Los argumentos pasados al script deben verificarse antes de proceder a la ejecución de las funciones, evitando errores futuros.
- Es importante dividir el código en funciones para facilitar la lectura y el reciclado del código. Lo agradeceréis cuando abráis el script unos meses después.
- Los errores han de tratarse (bloques de código en try...except) y, si son conocidos, informar al usuario de lo que ha pasado.
- ¡El código debe estar comentado! Una buena práctica es comenzar cada función con un docstring y comentar el resto del código con comentarios normales (utilizando #).
Y hasta aquí nuestro script de análisis de metadatos. Espero que os haya gustado y que os sirva para aprender, que es el objetivo de los scripts que os empezaré a traer más de vez en cuando en calidad de prueba de concepto.
Un saludo hackers!
hartek
Muy bueno el blog, lo estaré siguiendo ;). También comentarles que en Mi Diario Python abrimos una sección nueva sobre Libros Python, quizá alguno le interese :). Saludos y gracias por compartir.
ResponderEliminarGracias a tí por leernos Diego! Seguro le echaremos un vistazo!
Eliminar